















Data science and machine learning are frequently used in conjunction, so if you’re looking to develop a career in one of these, it’s important to know the differences between machine learning and data science. We need to clarify a few essential words that are related but different before we do that.
Artificial Intelligence – refers to intelligent decisions taken by machines at the same time as their human counterparts. It’s a study that allows machines to learn by experience and make it smart enough to perform human-like tasks. Let me send you a clear description of machine learning for this post.
Machine learning – is a subset of Artificial Intelligence. In the same way that humans learn with experience, machines can learn with data (experience) rather than simply following simple instructions. This is called machine learning. Machine learning uses three types of algorithms – supervised, unsupervised, and reinforced.

Deep learning – Deep learning is part of Machine learning, and is focused on artificial neural networks (think of neural networks close to our own human brains). Unlike machine learning, deep learning uses multiple layers and architectures algorithms to build an artificial neural network that learns and makes decisions on its own!
Big Data – A large collection of data that can be processed to recognize and process trends, patterns, and human behavior.
Data Science – How are all the big data analyzed? Ok, the machine learns on its own by machine learning algorithms, but how? Who gives the requisite inputs to the machine to construct algorithms and models? There’s no point in pretending that it’s data science. Data Science uses a range of techniques, algorithms, processes, and systems to collect, interpret and gain insights from data.
Artificial Intelligence involves both Machine Learning and Data Science linked to each other. Data science is therefore also a part (most common and perhaps most critical part) of AI.
As we see above, data science and machine learning are closely linked and provide valuable insights and generate the requisite patterns or ‘experience.’ In both, we use supervised learning techniques , i.e. learning from large data sets.
How are the two correlated?
Data Science is a wider area of research that uses algorithms and machine learning models to analyze and process data. In addition to research , data science also covers data integration, visualization , data engineering, deployment and business decisions.
Data Science vs Learning Machine
Data science focuses on data analysis and improved presentation, while machine learning focuses more on learning algorithms and learning from real-time data and experience.
Always note – data is the main focus of data science, and learning is the main focus of machine learning, and that is where the distinction lies.
To understand this difference more, let us take advantage of the case and see how data science and machine learning can be used to achieve the results we want you to achieve!
Let us say that you want to buy a laptop at abc.com. This is the first time you’ve visited abc.com and you’ve been searching all ranges of laptops. You use a number of filters to narrow down your choices, and out of the results you receive, you pick 1-7 of your laptop and compare them. When you have selected a laptop model, you can see a recommendation below the product – for a similar version at a cheaper price or with more functionality, or related laptop accessories that you have chosen, and so on. How does the website recommend these things to you? It has no history of you!
This is by data from millions of other people who might have attempted to buy the same laptop and searched/purchased other devices along the way. This makes the system automatically recommend the same thing to you.
Data science is the whole process of gathering data from users, cleaning up and filtering the data needed for evaluation, analyzing the filtered data for building patterns, identifying common trends, and creating a model for suggesting the same thing to other users, and eventually optimizing it.
So, Where is machine learning in all of this? Well, how are you going to create a model? Using machine learning algorithms. Based on the data collected and the patterns created, the system understands that these are the accessories that are normally purchased by other users of a specific device. That’s why it recommends the same thing to you on the basis of what it’s ‘experienced’ before.
Modeling is the most important step, since that is what enhances the overall business and lets the system understand human actions. If the right machine learning model is applied, this may mean more positive learning for the system as well as performance for the business model.
This step is called the data processing step – which is basically the machine learning phase of the data science lifecycle.
Data Modelling– How is machine learning working?
There are various types of machine learning algorithms, the most common being clustering, matrix factoring, content-based, recommendations, collaborative filtering, and so on. Machine learning requires five simple steps –
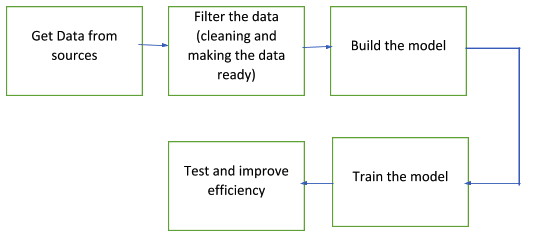
The vast collection of data that we obtain in the first phase is divided into the training set and the test set, and the model is built and tested using the training set. A large portion of the data is used for training purposes so that various input and output conditions can be reached and the model created is closest to the desired outcome (recommendation, human actions, patterns, etc.).
Once developed, the model is tested for efficiency and accuracy using the test data to enable cross-validation.
As we can see, Machine Learning can only be used during the data processing process of the Data Science Lifecycle. Data Science also requires machine learning.
Through machine learning, the machine can generate complex mathematical algorithms that do not need to be programmed by humans and can further improvise and develop programs on its own. Compared to conventional statistical analysis methods, machine learning is a great way to collect and process the most complex collection of big data, making data science simpler and less unpredictable.
In addition, computers appear to be more reliable and have a better memory than humans, they can learn and generate accurate results based on experience. We get fast algorithms and data-driven models without the human-possible errors.
| Machine Learning | Data Science |
| It is a part of data science where methods and techniques are used to build algorithms so that the computer can learn from data through experience. | It is an interdisciplinary field where unstructured data is cleaned, interpreted, analyzed and market technologies are discarded. |
| Machine learning can not exist without data science, as data must first be prepared to create, train and test the model. | Data science can work with manual methods as well though they are not as efficient as machine algorithms |
| It comes only in the data modeling stage of data science. | It has a vast scope |
| Machine learning is a single step in data science that uses the other steps of data science to create the best suitable algorithm for predictive analysis | Data science is a complete process. |
| Knowledge of SQL is not necessary. Programs are written in languages like R, Python, Java, Lisp etc | Knowledge of SQL is necessary to perform operations on data. |
| Machine learning is a subset of AI and also a connection between AI and data science since it evolves as more and more data is processed. | Data science is not a subset of AI. |
| Machine learning cannot exist without data science as data has to be first prepared to create, train and test the model. | Data science can work with manual methods as well though they are not as efficient as machine algorithms |
How do you choose between data science and machine learning?
Oh, you can’t pick one of them. Data science and machine learning go hand in hand. Machines can not learn without data, and Data Science is best achieved with machine learning as discussed above. In the future, data scientists will need at least a basic understanding of machine learning to model and interpret the big data that is produced every day.
If you’re just beginning your career, or if you’re from different backgrounds like Java or. NET, there’s nothing to think about. The science of data is vast, but not difficult. Since it has several phases, the work of a data scientist is divided into various sub-fields. Once you’ve sorted the core concepts, go deeper into machine learning and deep learning through the tutorial links offered. Whether or not you have programming experience, you will become a good data scientist by studying the resources and techniques required to work on data and gain good domain knowledge.
The Review
Shadow Tactics: Blades of the Shogun
A wonderful serenity has taken possession of my entire soul, like these sweet mornings of spring which I enjoy with my whole heart. I am alone, and feel the charm of existence in this spot, which was created for the bliss of souls like mine.
PROS
- Good low light camera
- Water resistant
- Double the internal capacity
CONS
- Lacks clear upgrades
- Same design used for last three phones
- Battery life unimpressive
Review Breakdown
-
Design
-
Performance
-
Camera
-
Battery
-
Price



{kind=link}