















Large Language Models (LLMs) have drastically altered natural language processing (NLP), allowing machines to understand, generate, and interact with human language in previously unimaginable ways. The most important LLMs are GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers). These models represent an enormous improvement in the ability of machines to process language, thanks to their sophisticated architectures and massive training datasets.
In this article, we will explore the architecture and functionality of these popular LLMs, trace their evolution, and examine their applications in various NLP tasks.
The Evolution of Large Language Models
From RNNs to Transformers
Models based on RNNs and LSTM networks ruled the natural language processing (NLP) scene prior to the introduction of LLMs such as GPT and BERT. The models’ inability to handle long-range dependencies and parallelisation severely limited their scalability, even though they were good at capturing textual sequential information.
A watershed moment in natural language processing occurred in 2017 with the release of the Transformer model by Vaswani et al. Thanks to its self-attention mechanism, the Transformer architecture overcame RNNs’ shortcomings by training a model that could take into account every word in a sentence at once, thereby improving its ability to grasp contextual relationships. The creation of LLMs such as GPT and BERT was made possible by this breakthrough.
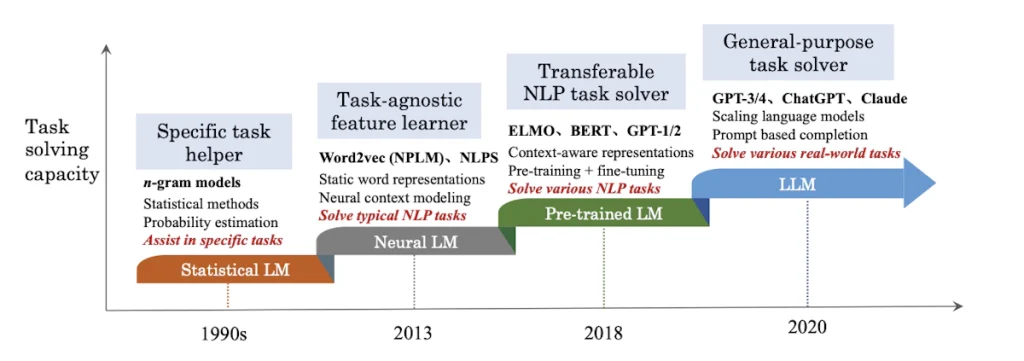
GPT: Generative Pre-trained Transformer
Architecture
OpenAI’s GPT uses the Transformer decoder design as its foundation. The two-stage training process, which includes pre-training and fine-tuning, is its main innovation.
- Pre-training: During this stage, GPT is trained on a massive corpus of text data to predict the next word in a sentence. This task, known as language modelling, helps the model learn a wide range of linguistic patterns, from syntax to semantics.
- Fine-tuning: After pre-training, GPT is fine-tuned on a smaller, task-specific dataset, allowing it to adapt to particular NLP tasks such as text generation, translation, or summarization.
Functionality
GPT is an effective tool for many natural language processing applications due to its capacity to produce coherent and contextually relevant text. But it can’t grasp sentences where later words affect meaning because it only takes left-side context into account (unidirectional context).
Applications
- Text Generation: GPT excels at generating human-like text, making it useful for content creation, automated storytelling, and chatbots.
- Conversational AI: GPT-powered models like ChatGPT have become the backbone of many virtual assistants, capable of engaging in complex dialogues with users.
- Code Generation: GPT-3, an advanced version of GPT, has been adapted to generate code snippets, helping developers automate routine coding tasks.
BERT: Bidirectional Encoder Representations from Transformers
Architecture
Unlike GPT, which is based on the Transformer decoder, BERT is built on the Transformer encoder architecture. The key distinction between the two lies in how they handle context:
- Bidirectionality: The training of BERT allows it to think bidirectionally by taking into account the left and right contexts of a word at the same time. This improves BERT’s performance on many natural language processing tasks by enabling it to grasp more complex word-to-sentence relationships.
- Pre-training Objectives: BERT introduces two novel pre-training tasks, Masked Language Modeling (MLM) and Next Sentence Prediction (NSP). In MLM, random words in a sentence are masked, and BERT is trained to predict them. In NSP, BERT is trained to determine if two sentences follow each other, enabling it to understand the relationship between sentences.
Functionality
BERT’s bidirectional nature makes it particularly effective for tasks that require a deep understanding of context, such as question answering and sentiment analysis. However, because BERT is not generative, it is not used for text generation tasks.
Applications
- Question Answering: BERT is widely used in systems like Google’s search engine to provide precise answers to user queries.
- Sentiment Analysis: BERT-powered models can accurately detect sentiment in text, making it valuable for social media monitoring and customer feedback analysis.
- Named Entity Recognition (NER): BERT can identify and classify entities (like names, dates, and locations) within a text, which is essential for information extraction tasks.

Beyond GPT and BERT: The Next Generation of LLMs
As impressive as GPT and BERT are, the field of NLP continues to evolve rapidly, with newer models pushing the boundaries of what is possible.
GPT-4 and Beyond
OpenAI’s GPT-4, the successor to GPT-3, introduces even larger model sizes and improved training techniques, resulting in more coherent and context-aware text generation. GPT-4’s advancements include better handling of multi-turn conversations and the ability to generate longer and more complex pieces of text.
BERT Variants: RoBERTa, ALBERT, and DistilBERT
Several variants of BERT have been developed to address specific limitations:
- RoBERTa: An optimized version of BERT that improves training efficiency and performance by modifying the training objectives and hyperparameters.
- ALBERT: A lighter version of BERT that reduces model size without sacrificing accuracy, making it more suitable for resource-constrained environments.
- DistilBERT: A distilled version of BERT that is smaller and faster while maintaining much of the original model’s performance, ideal for real-time applications.
Multimodal LLMs
A key capability of LLMs going forward will be their capacity to process a variety of modalities, including text, pictures, and audio. Models such as CLIP and DALL·E from OpenAI integrate text and image understanding, allowing them to create images based on textual descriptions or comprehend images with greater context.
Conclusion
Natural language processing has undergone a sea change thanks to Large Language Models such as GPT and BERT, which allow computers to comprehend and produce human language with previously unseen levels of accuracy. From sentiment analysis to text generation, their architectures have revolutionised natural language processing (NLP).
More complex models that can integrate various modalities and comprehend context in ways that resemble human cognition will likely be developed as LLMs advance. These models will be able to handle tasks that are becoming ever more difficult. Data scientists and natural language processing (NLP) fans would do well to keep up with these advancements, since LLMs’ research and commercial uses are only going to grow, opening up exciting new avenues for AI.


{kind=link}